

欢迎来到AIGC的魔法世界

参考在线课程https://modelscope.cn/learn/1582?pid=1577 [1]
特别鸣谢: 阿里魔搭ModelScope平台
- ps: 其实网站每个视频最后面都有相应的摘要
本文旨在对课程核心内容进行记录与提炼,并融入了一些个人的理解和思考。文中若有任何疏漏或理解不当之处,敬请各位读者不吝指正,共同交流探讨(^_−)☆
- 鉴于文本生成技术已广为人知,本文将重点聚焦于当前发展迅速且形式新颖的非文本内容生成,主要涵盖图像、音频及视频生成三大领域。
侵删
原理
生成模型的演化历程
生成模型的本质是什么?
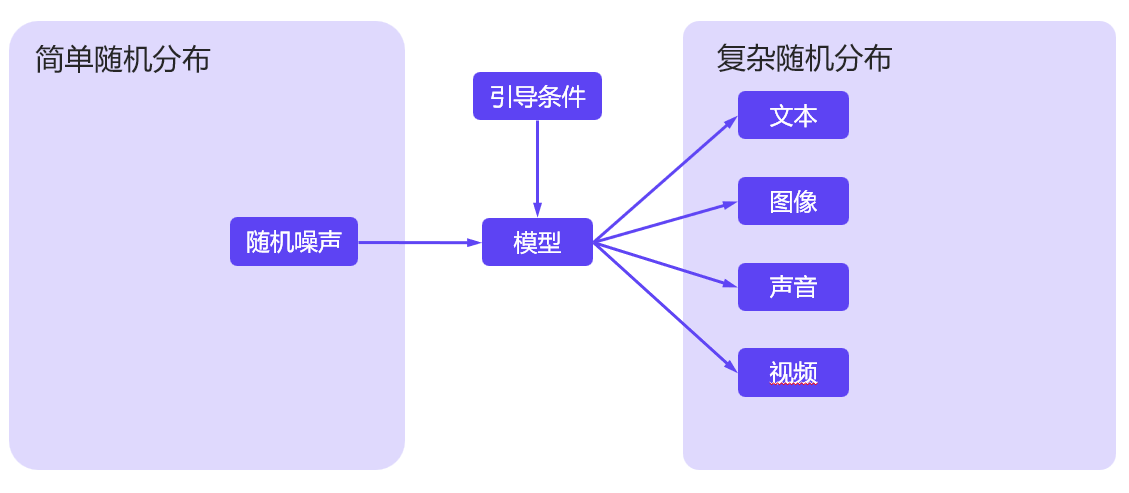
生成模型的本质,在于将一个服从简单随机分布(如高斯分布)的噪声与一个引导条件作为输入,通过模型复杂的非线性映射,将其转化为一个服从**目标数据真实分布(复杂随机分布)**的输出,这些输出最终表现为我们所见的图像、音频或视频等形式。
随机噪声:
- 它是生成多样性的来源。对于一个确定的模型,如果仅仅输入固定的引导条件(如提示词), 理论上其输出应该是恒定的,因为模型本身是确定性的张量运算
(就算是dropout层,也只是在训练的时候其作用,不会影响测试时的确定性)。然而在实践中,即使用户输入完全相同的提示词,每次生成的结果却也各不相同。这是因为模型在每次生成时,都会引入一个用户无法直接感知的随机噪声(通常由随机种子seed控制)。这个初始噪声的微小差异,经过模型的放大和转换,最终导致了输出结果的多样性。
- 它是生成多样性的来源。对于一个确定的模型,如果仅仅输入固定的引导条件(如提示词), 理论上其输出应该是恒定的,因为模型本身是确定性的张量运算
引导条件:
- 这是用户可以控制的,用于指导生成方向的输入,例如提示词、**参考图像 (如线稿) **等
生成式模型vs检索系统:
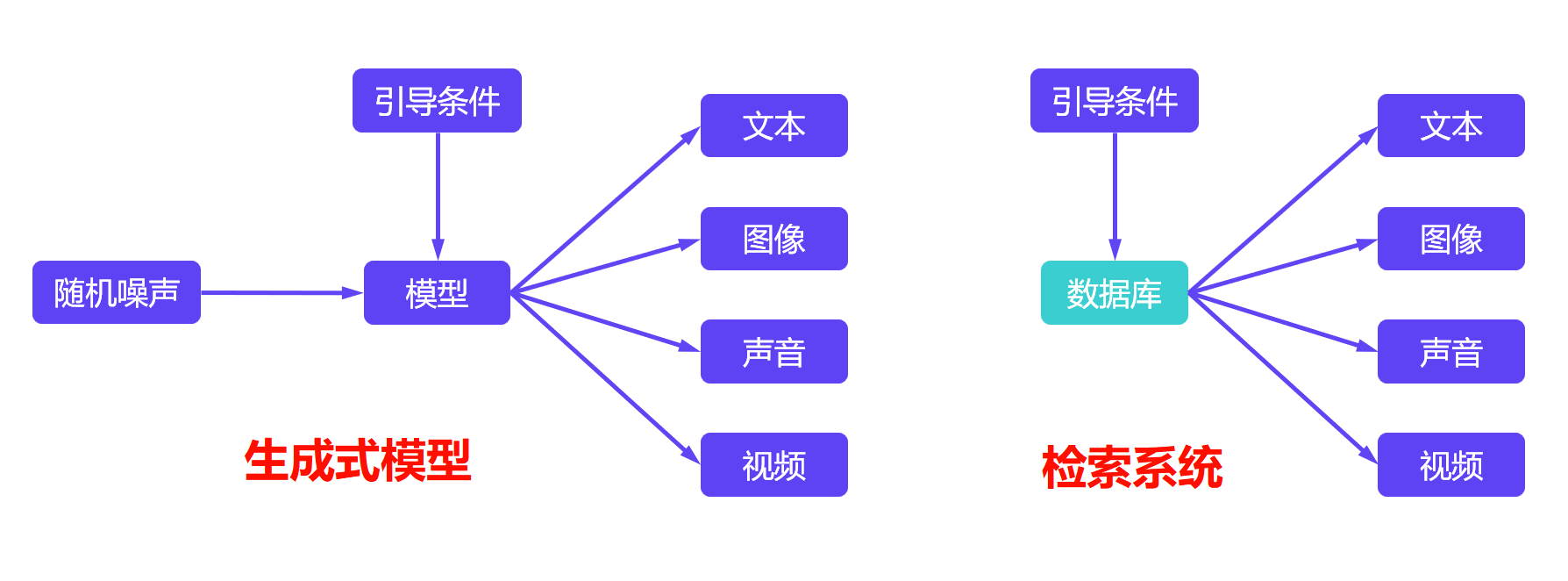
从概念上讲,生成式模型与检索系统存在一个有趣的类比。两者都能根据用户输入的引导条件 (如文本) 返回相关的图像。它们的核心区别在于输出空间的性质:检索系统的输出空间是离散的 (从有限的数据中选取,是空间中离散的点), 而生成模型的输出空间是连续的。
这种连续性正是基于一个核心理念:与现代NLP模型类似,先进的图像生成模型同样在名为 “潜在空间(Latent Space)” 的高维向量空间中运作。 无论是输入的文本提示词,还是生成过程中的图像特征,都会被编码为这个空间中的向量(Embedding)。在这个空间中,语义相近的概念在空间位置上也相互靠近。关于潜在向量空间的理解,最早可以追溯到Word2Vec的词向量,可见这篇文章的解释
因此,生成模型可以被视为一种平滑的检索。举个例子:它不仅能够找到代表程序员和猩猩的向量区域,更能在这些区域之间进行插值,从而创造出一个在训练数据中从未出现过,但语义上融合了两者特征的全新向量,最终解码为**程序“猿”**的图像。而离散的检索系统只能输出向量数据库中已有的离散点。
生成式模型的演变
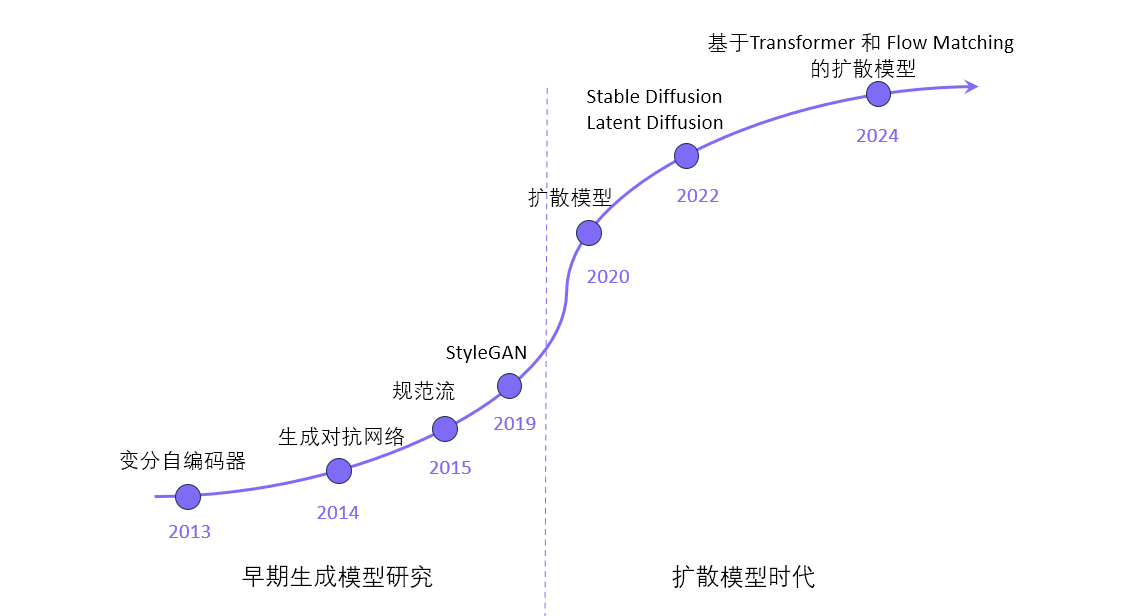
如果要深入学习这个领域的话,或许可以参考这个时间脉络去进行学习。毕竟论文作者很多时候都默认读者知道一些前置的模型或概念,若是不提前了解可能会在理解上遇到一些困难
- 当前主流的模型为 扩散(Diffusion)模型
- 其基本原理可以直观地理解为:从一张纯粹的噪声图开始,多步迭代,逐步去噪,在引导条件的指引下,最终“还原”出一张清晰的图像
- 因为去噪过程实际主要依赖的是对噪声的预测能力,所以训练过程与生成过程恰好相反:向真实图像逐步叠加噪声,让模型在每一步都学习如何预测并移除被添加的噪声
实践
如果手上缺少算力的话可以在魔搭社区的AIGC专区玩玩 https://modelscope.cn/aigc/home
如果有算力并且比较爱折腾的话,可以考虑使用魔搭团队开源的DiffSynth-Studio引擎[2]
模型推理
文生图
文生图是最基本的生图模式,也是应用最简单,普及最广泛的一种生成模式。
只需要用户输入一段文本形式的提示词,模型就能够生成一张相关的图像。
提示词写作技巧
前面我们已经提到,用户输入的提示实际上是对模型的一种引导条件,所以很多时候我们需要通过提示词对图像生成的内容进行引导,提示词的质量直接或间接地决定了生成图像的质量。容易理解,为了更好地指导模型,我们可能需要一些摄影的技巧;可能需要一些构图的知识 不过这大抵上属于是锦上添花,即便不懂摄影或构图,只要有审美细胞,都能进行调整
关于写作提示词的具体技巧(范式)有
- 提示词反推 —— 已经有了一张图,可以在这张图的基础上反推出提示词
- 提示词润色 —— 更精细的描述
- 负向提示词 —— 不要什么
- 翻译
因为有些图像模型,并不支持中文输入,但实际上翻译这一步有些时候可以省去。虽然很多时候使用英文提示词往往比使用中文提示词表现更好,但是我非常认可一个观点——概念优于语言。与其纠结prompt的语言,不如思考如何对AI描述清楚你的需求 [3]
但事实上,我们可以让大语言模型来生成提示词,然后再自行调整
可以参考的工具有很多[4]:
Learning Prompt: 老是全权依赖工具也不是回事,可以在这里学些提示词设计经验
PromptPort: 有很多现成的Prompt模版可以参考交流
- FlowGPT已经转型应用商店了,不太好搞。但是PromptPort体验还不错,提示词模版涉及各个领域,而且基本都有中英两版,
可以阅读中文版快速理解然后复制英文版使用
- FlowGPT已经转型应用商店了,不太好搞。但是PromptPort体验还不错,提示词模版涉及各个领域,而且基本都有中英两版,
魔咒百科词典:魔法导论工具, 简单易用的AI绘画tag生成器
- 在下第一次接触AI绘画的时候就听到有人喜欢使用“魔法导论”这样的说法来指代这个技术,这个比喻实在是有趣又贴切,因为基本的文生图AI绘画的的确确给人一种魔法的感觉,尤其是普通人第一次接触。只需要念出一连串咒语
(关键词提示词),再经由神秘的不可知域(模型黑箱)赐福,就能够创造出令人惊叹的“无上奇迹”(让一个普通人在极短的时间内创造出精密的图像)。同时它也似魔法一般,时而成功时而失败,不可预测。 - 而这份“魔咒百科词典”,就是在这个魔法语境下的 提示词 模版啦。只是AI绘画的提示词往往都是关键词的形式存在的,所以正巧就变成了魔咒词典。
客观地说,我们使用什么样风格的提示词其实主要取决于模型使用了什么样的文本编码器,训练的时候使用了什么样的文本描述风格。虽然早期的风格都是偏咒语形式的,但现在主流模型已经开始进化到可以支持偏向自然语言的提示词
- 在下第一次接触AI绘画的时候就听到有人喜欢使用“魔法导论”这样的说法来指代这个技术,这个比喻实在是有趣又贴切,因为基本的文生图AI绘画的的确确给人一种魔法的感觉,尤其是普通人第一次接触。只需要念出一连串咒语
可控生成技术
除了提示词这种引导形式外,还有很多其他形式的引导条件,如图所示
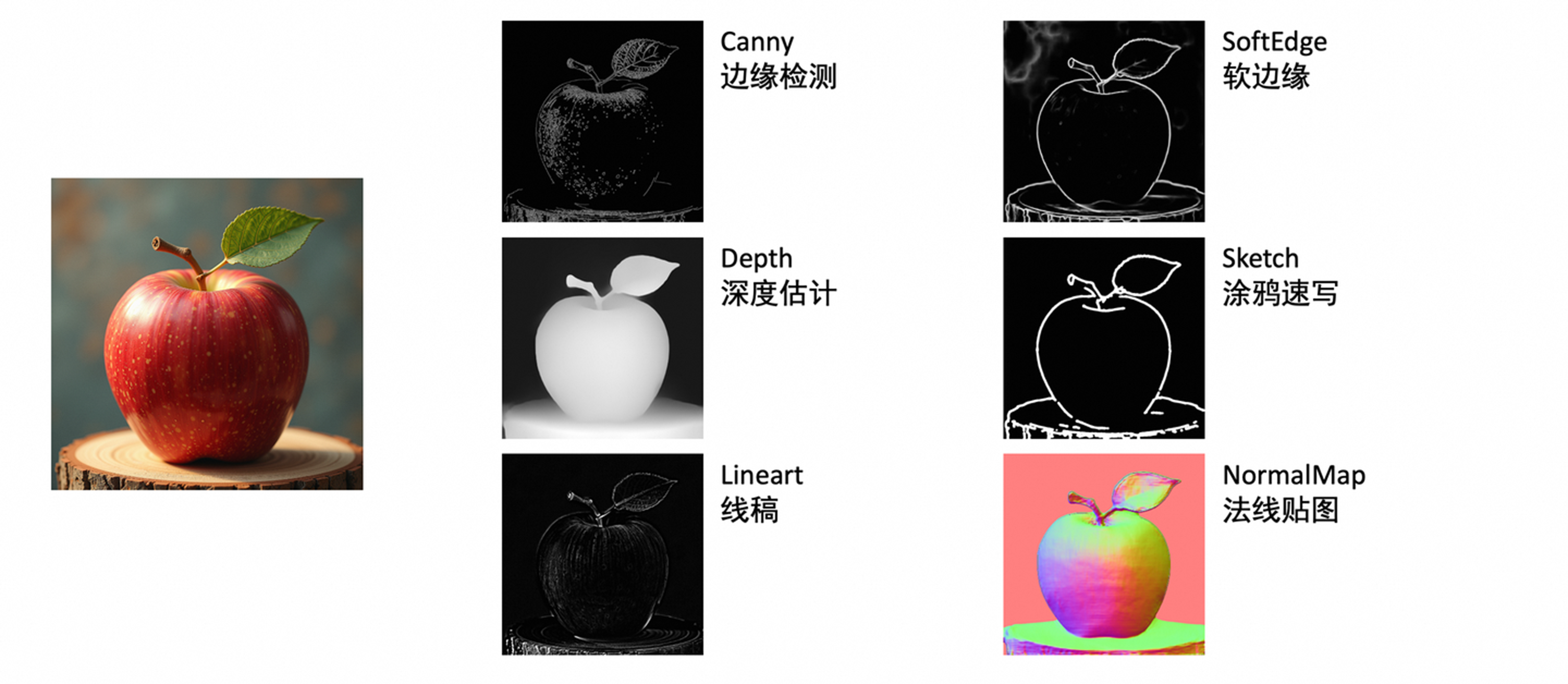
可控生成技术为生成过程提供了远超文本提示词的、精细化的空间和结构控制,在实践中已得到广泛应用,其中非常具有代表性的框架就是ControlNet [5]
ControlNet及其衍生技术,允许用户输入一张控制图(如线稿、深度图、人体姿态骨骼图等),在保持原图结构、姿态或构图的基础上,由扩散模型进行内容的重绘和填充。
不难想象,这是在生成领域至关重要的一项技术。因为人类多数时候难以仅用自然语言把需求完美地进行传递。在这项技术出现前,仅靠提示词进行图像生成,就像是在开盲盒,充满了随机性。
例如在ComfyUI这类基于节点的工作流编排工具中,上述可控生成技术就是核心组成部分。一个节点的输出(如姿态检测结果)可以作为下一个生成节点的控制输入,从而实现复杂的多步生成任务。
ps: 从某种意义上来讲LoRA或许也算得上是一种控制,只不过是属于风格、角色或概念层面的控制,而非空间结构控制。
图像融合技术
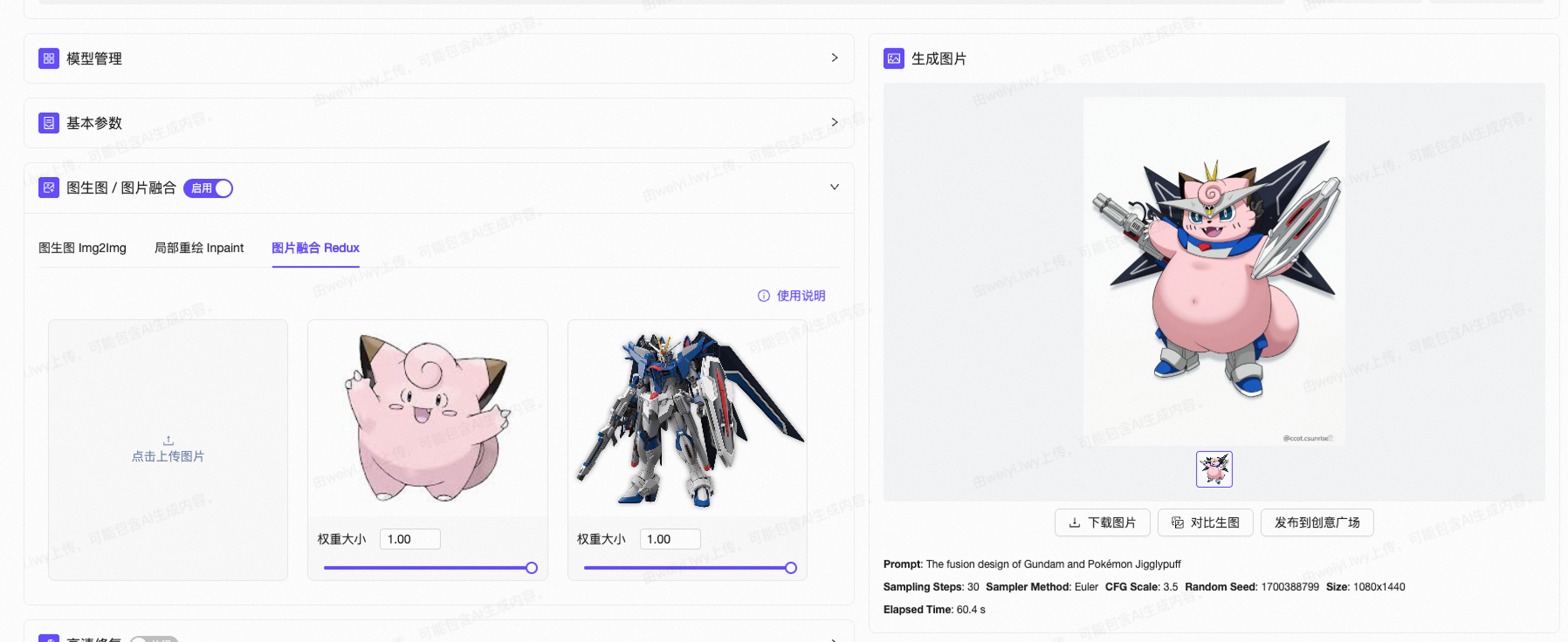
试试融合一个篮球和一只鸡会怎么样(x
工作流式应用搭建
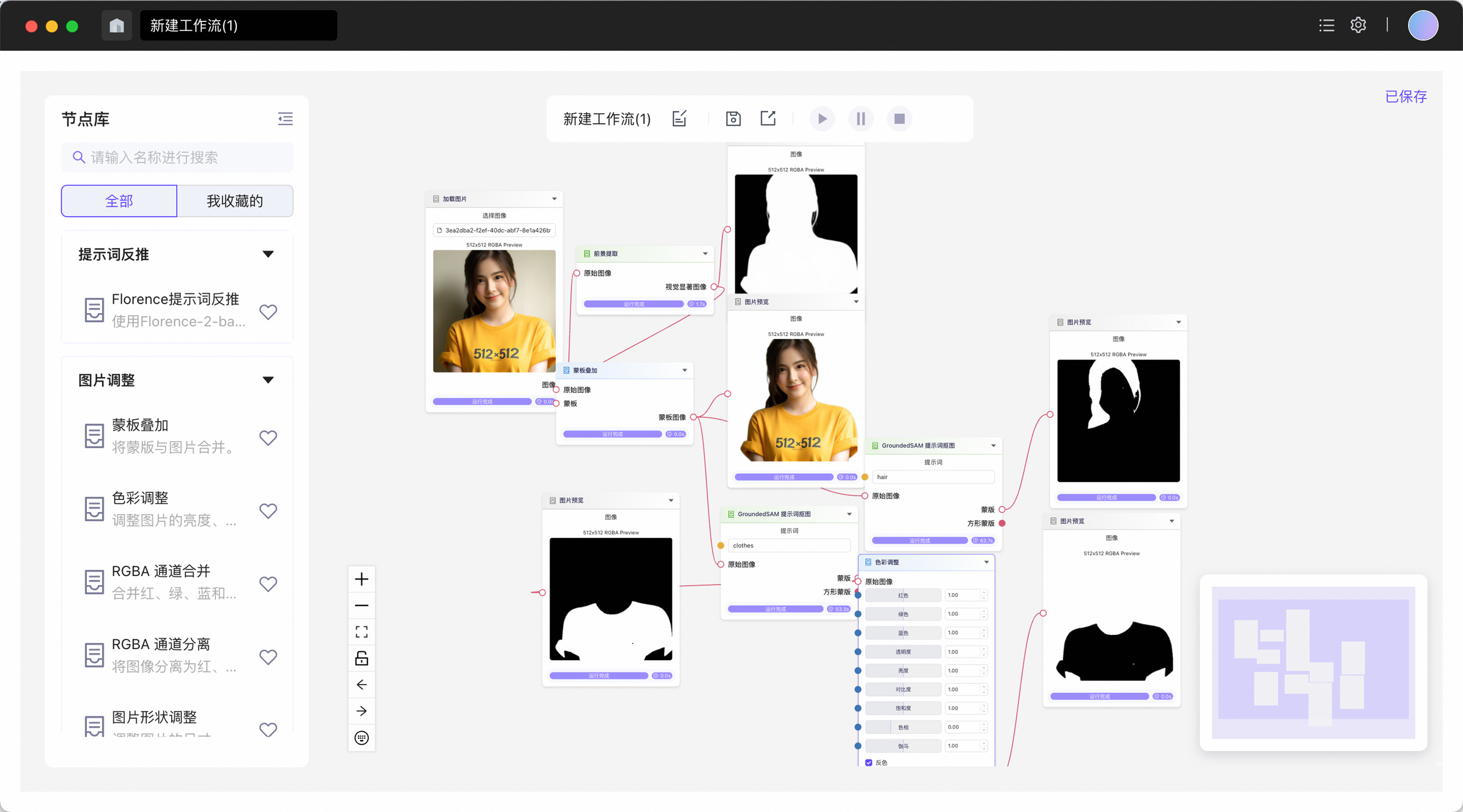
想象一下现实中画师的工作,大多数画师也不会一笔成稿,而是经历线稿到上色,人物形体到饰品等过程。让AI也像人类一样每次专注于一个任务可以取得更好的效果。
模型训练
LoRA
全称Low Rank Adaptation
一种在预训练的图像生成模型训练完成后,低成本拓展生成能力的技术[6][7]
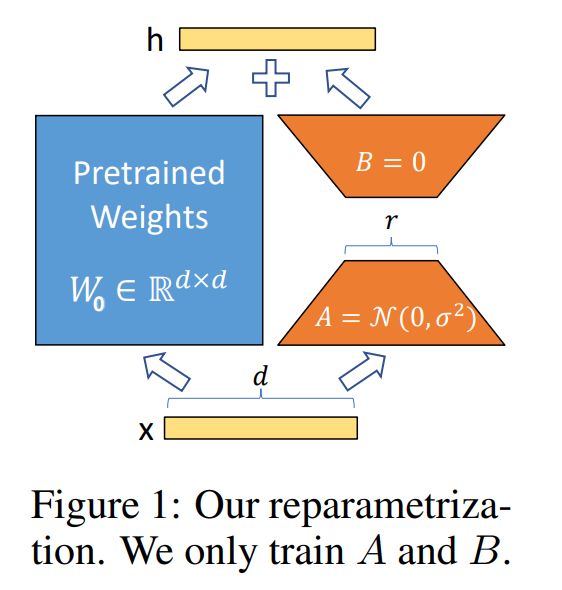
左侧蓝色矩阵为预训练模型原先训练好的参数矩阵
于是我们可以增加两个小矩阵
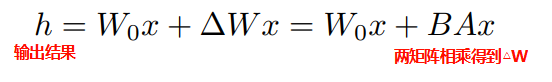
- ps: 在实际应用场景中,往往还会给增量矩阵
先乘上一个缩放因子 , 从而控制LoRA的力道。 - 从这个公式可以看出,同时使用多个LoRA是可行的,只需要加上多项即可
因为r要远小于d,所以两个小矩阵的参数量
图中B=0是为了保证在训练开始的时候,能够沿用原模型的能力, 因为训练开始的时候,BA为零矩阵,加到
但是注意,此时A绝不能为0!
- 试想一下A和B同时为0会发生什么,梯度会彻底消失!简单想象一下,有一个表达式
, 如果 为0,那么对 求导的时候,导数为 ,那么只要 不为0, 就有梯度,就有可能可以训练变化;但如果此时 为0,则梯度为0,这个参数完全不参与最后的预测,也自然不会被训练到。反而反之,因为 地位和 地位相同,若 =0, 不为0,则对 求导仍可训练。
LoRA的普适性
LoRA作为一种参数高效微调 Parameter-Efficient Fine-Tuning, PEFT), 其核心是“低秩适应”这一数学思想,因此它的应用范围远不止图像生成领域。基于对上述原理的观察,在下认为,任何模型,只要其包含权重矩阵,都可以利用LoRA进行微调,甚至可以有选择地对部分权重矩阵进行微调。ps: 有文章明确提到了对Transformer使用LoRA[8]。
- 前提:模型在微调过程中,参数的改变量是**低秩(Low-Rank)**的。因此,无需更新整个庞大的原始权重矩阵 W_0,只需学习一个低秩的增量矩阵
使用LoRA
即便LoRA大大降低了成本,由于模型的参数量很大,使用个人消费级显卡仍然可能很难训练。o(╥﹏╥)o
然天无绝人之路,我们还有魔搭社区的LoRA训练功能可以免费使用!
而且阿里的工程师大佬说,他们是打算长期让这个功能免费的,本身便没有打算盈利,而是更多地希望推动技术的发展。(✧∇✧)
其实就算不是自行训练LoRA,使用社区里别的大佬训好的LoRA试玩一下也是很有意思的。下面这是我使用社区中miratsu style LoRA模型,参考相关提示词简单生成的图像 —— 无恶意 ^(* ̄(oo) ̄)^

训练LoRA
为了训练LoRA我们需要:
- 原始图片
- 描述该图片的文本,即提示词
大部分情况下,我们只有图片但没有提示词,所以需要进行图片打标
- AI打标:效果还是不错的;有针对打标任务特化过的模型——Florence2 / JoyCaption Beta-1
- 手动打标: AI打标结果无法覆盖主体部分细节或者存在偏差,可以手动修改
推荐模型
图像生成工具
- 魔搭 AIGC 图像生成专区:https://modelscope.cn/aigc/imageGeneration?tab=advanced
- 开源项目 DiffSynth-Studio:https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/flux
视频生成工具
- 魔搭 AIGC 视频生成专区:https://modelscope.cn/aigc/videoGeneration
- 开源项目 DiffSynth-Studio:https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo
音频生成工具
- CosyVoice:https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B
- ACE-Step:https://modelscope.cn/studios/ACE-Step/ACE-Step
API服务
免费云计算资源(A10,24G显存暂时无法支持大模型推理和训练)
魔搭 Notebook:https://modelscope.cn/my/mynotebook
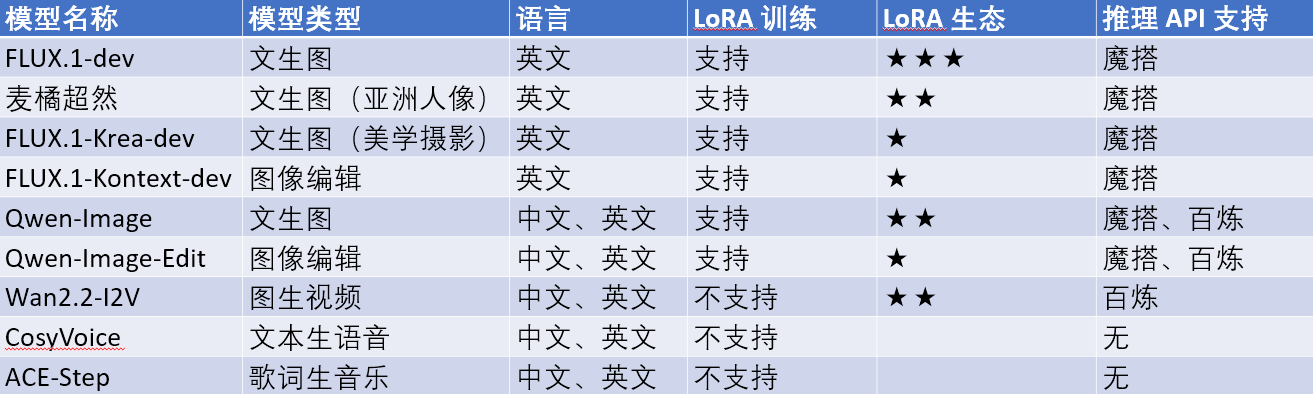
推荐技术路线
针对于课程中提到的如何搓一个AI互动小游戏的推荐技术路线:
训练图像生成模型的 LoRA(使用魔搭社区在线训练)
编写脚本、分镜描述(手动编写或使用 LLM 生成)
批量生成图像(使用魔搭 Notebook 调用 API)
将部分图像转为视频(使用魔搭在线生成,或使用其他工具)
生成配音(使用 CosyVoice 和 ACE-Step)
整合资源
前沿
视频生成模型
魔搭 AIGC 视频生成专区:https://modelscope.cn/aigc/videoGeneration
音频生成模型
ACE-Step模型
CosyVoice
多模态统一的模型架构
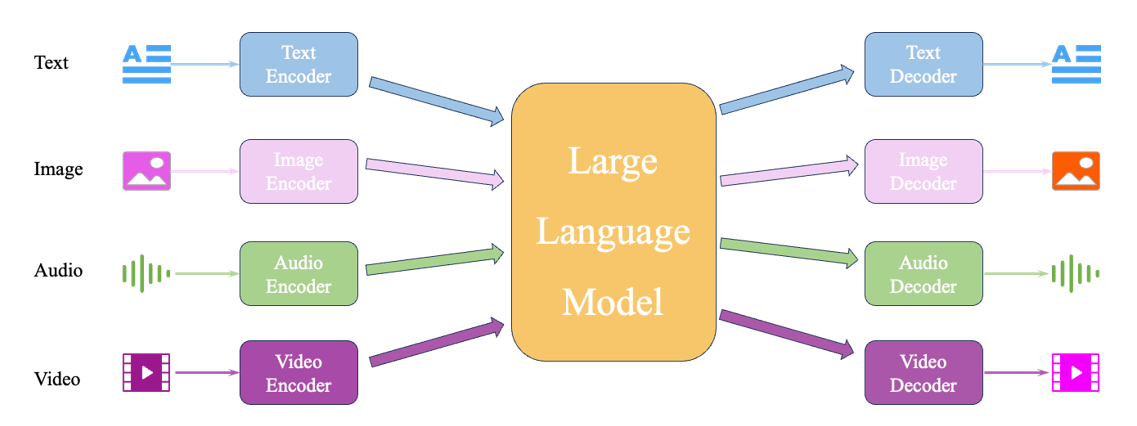
虽然这种能够同时处理多个模态的“万能模型”听起来很美好,但事实上现阶段它就像是……啥都能干,但啥都不精 —— 博而不精。即模型虽然具备多种能力,但在任一单项任务上的表现,通常难以超越为该任务专门优化的顶尖模型。
但是学术界和工业界仍然在乐此不疲地研究,仍然值得期待
展望
对齐训练与伦理道德

因为AI的能力是从数据集上学习得来的,而数据集又来自于人类,这意味着AI不可避免地会学习到一些属于人类的偏好甚至偏见,导致其输出内容可能带有某些特定色彩。
AI始终是服务于人类的工具
其善恶之分
依赖于执掌者之心
额外课程
图像、音频、视频、html实践案例
Qwen-Image文生图、微调、编辑原理与实践
- 魔搭社区小编 . AIGC多模态生成:从实践到原理(附:从0手搓一个AI互动剧情小游戏). ModelScope, 2025 ↩
- ModelScope team. DiffSynth-Studio. GitHub, 2025 ↩
- . 探讨:中文提示词和英文提示词的效果区别. LINUX DO, 2025 ↩
- 知白守黑. Prompt资源精选|你想要的AI提示词都在这里了. 知乎, 2025 ↩
- Rocky Ding. 深入浅出完整解析ControlNet核心基础知识. 知乎, 2025 ↩
- Hu, Edward J., et al. LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685, 2021 ↩
- 大师兄. LoRA(Low-Rank Adaptation)详解. 知乎, 2023 ↩
- Dreamweaver. 大模型的领域适配 —— Parameter-Efficient Fine-Tuning (PEFT). 知乎,2023 ↩
- 标题: 欢迎来到AIGC的魔法世界
- 作者: Prometheus0017
- 创建于 : 2025-09-02 23:48:03
- 更新于 : 2025-09-07 21:42:57
- 链接: https://blog-seeles-secret-garden.vercel.app/2025/09/02/欢迎来到AIGC的魔法世界/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


